Simulado TRE-MA | Analista Judiciário – Análise de Sistemas | CONCURSO
SIMULADO TRE-MA | ANALISTA JUDICIÁRIO – ANÁLISE DE SISTEMAS
INSTRUÇÕES DESTE SIMULADO
OBJETIVOS DO SIMULADO
Aprimorar os conhecimentos adquiridos durante os seus estudos, de forma a avaliar a sua aprendizagem, utilizando para isso as metodologias e critérios idênticos aos maiores e melhores concursos públicos do País, através de simulado para concurso, prova de concurso e/ou questões de concurso.
PÚBLICO ALVO DO SIMULADO
Candidatos e Alunos que almejam sua aprovação no concurso TRE-MA para o cargo de Analista Judiciário – Análise de Sistemas .
SOBRE AS QUESTÕES DO SIMULADO
Este simulado contém questões de concurso da banca IESES para o concurso TRE-MA. Estas questões são especificamente para o cargo de Analista Judiciário – Análise de Sistemas , contendo Banco de Dados que foram extraídas de concursos públicos anteriores, portanto este simulado contém os gabaritos oficiais do concurso.
ESTATÍSTICA DO SIMULADO
O simulado TRE-MA | Analista Judiciário – Análise de Sistemas contém um total de 20 questões de concursos com um tempo estimado de 60 minutos para sua realização. O assunto abordado é diversificado para que você possa realmente simular como esta seus conhecimento no concurso TRE-MA.
RANKING DO SIMULADO
Realize este simulado até o seu final e ao conclui-lo você verá as questões que errou e acertou, seus possíveis comentários e ainda poderá ver seu DESEMPENHO perante ao dos seus CONCORRENTES. Venha participar deste Ranking e saia na frente de todos. Veja sua nota e sua colocação no RANKING e saiba se esta preparado para conseguir sua aprovação.
Bons Estudos! Simulado para Concurso é aqui!
- #119167
- Banca
- IESES
- Matéria
- Banco de Dados
- Concurso
- TRE-MA
- Tipo
- Múltipla escolha
- Comentários
- Seja o primeiro a comentar
(1,0) 1 -
No procedimento em PL/SQL ORACLE abaixo, o parâmetro IN serve para:
PROCEDURE define_atividade
(ultima_data_in IN DATE,
tarefa_desc IN OUT VARCHAR2,
prox_data_out OUT DATE)
- a) Aplicar um desconto e retroagir a prox_data_out.
- b) Passar valores dentro do procedimento define_atividade.
- c) Não faz nenhuma diferença e não implica em nada ao parâmetro.
- d) Incluir um novo registro na tabela DATE.
- #119168
- Banca
- IESES
- Matéria
- Banco de Dados
- Concurso
- TRE-MA
- Tipo
- Múltipla escolha
- Comentários
- Seja o primeiro a comentar
(1,0) 2 -
NO PL/SQL do ORACLE, o pacote DBMS_CRYPTO permite a escolha de uma constante que determina o algoritmo de criptografia e o tamanho da chave usada. A constante ENCRYPT_3DES_2KEY tem um tamanho de chave de:
- a) 112
- b) 192
- c) 56
- d) 256
- #119169
- Banca
- IESES
- Matéria
- Banco de Dados
- Concurso
- TRE-MA
- Tipo
- Múltipla escolha
- Comentários
- Seja o primeiro a comentar
(1,0) 3 -
Uma das razões para um analista realizar a desnormalização de um projeto de banco de dados é quando:
- a) É necessário construir consultas DDL.
- b) Para agilizar a evolução do projeto de banco de dados e compatibilidade de charset.
- c) Não existe escolha, pois a desnormalização é obrigatória para qualquer tipo de projeto de banco de dados.
- d) Ele encontra a necessidade de reduzir a quantidade de associações (JOIN) em consultas e, consequentemente reduzindo o uso de recursos do SGBD.
- #119170
- Banca
- IESES
- Matéria
- Banco de Dados
- Concurso
- TRE-MA
- Tipo
- Múltipla escolha
- Comentários
- Seja o primeiro a comentar
(1,0) 4 -
Uma função PIPELENED, que é uma função de tabela em PL/SQL ORACLE produz como resultado:
- a) Um result set como uma coleção e o faz de forma assíncrona.
- b) Um novo charset para a respectiva tabela.
- c) Um túnel invertido de dados para o banco.
- d) Uma conexão mais segura e estável.
- #119171
- Banca
- IESES
- Matéria
- Banco de Dados
- Concurso
- TRE-MA
- Tipo
- Múltipla escolha
- Comentários
- Seja o primeiro a comentar
(1,0) 5 -
A função no POSTGRESQL abaixo serve para:
CREATE OR REPLACE FUNCTION addition (integer,
integer) RETURNS integer
AS $$
DECLARE retval integer;
BEGIN
SELECT $1 + $2 INTO retval;
RETURN retval;
END;
$$ LANGUAGE plpgsql;
- a) Somar dois valores inteiros e retornar um valor inteiro.
- b) Encontrar as duas constantes $1 e $2 em uma das tabelas do banco de dados.
- c) Selecionar duas tabelas e retornar uma coluna inteira de uma das duas tabelas.
- d) Definir qual dos dois número é um número primo.
- #119172
- Banca
- IESES
- Matéria
- Banco de Dados
- Concurso
- TRE-MA
- Tipo
- Múltipla escolha
- Comentários
- Seja o primeiro a comentar
(1,0) 6 -
O particionamento em Data Warehouse apoia o gerenciamento de data sets. Onde o particionamento pode ser aplicado e quais são os tipos de particionamento:
- a) Pode ser aplicado em tabelas e índices. Os tipos de particionamento são: vertical e horizontal.
- b) Pode ser aplicado em chaves. Os tipos de particionamento são: direto e indireto.
- c) Pode ser aplicado em função. Os tipos de particionamento são: invertido e parcial.
- d) Pode ser aplicado em procedures. Os tipos de particionamento são: pleno e parcial.
- #119173
- Banca
- IESES
- Matéria
- Banco de Dados
- Concurso
- TRE-MA
- Tipo
- Múltipla escolha
- Comentários
- Seja o primeiro a comentar
(1,0) 7 -
Os índices são elementos fundamentais em um projeto de Data Warehouse. Os tipos de índices usados em sistemas de Data Warehouse são:
- a) Índice invertido.
- b) Índice bitmap e índices join.
- c) Round índice.
- d) Índices analíticos semânticos.
- #119174
- Banca
- IESES
- Matéria
- Banco de Dados
- Concurso
- TRE-MA
- Tipo
- Múltipla escolha
- Comentários
- Seja o primeiro a comentar
(1,0) 8 -
O POSTGRESQL possui uma relação de funções que apoiam seus serviços. Dentre elas, a função cume_dist() do POSTGRESQL é usada em consultas (query) para:
- a) Conta a distancia entre duas linhas.
- b) Calcular o ranking relativo de cada linha. O resultado considera a quantidade de linhas anteriores ao da linha corrente dividida pelo número total de linhas no resultado.
- c) Distancia o conjunto de linhas selecionadas da linha corrente.
- d) Acumular linhas distantes da linha corrente. A função é calcula fazendo uma contagem de linhas e antes de gerar o resultado.
- #119175
- Banca
- IESES
- Matéria
- Banco de Dados
- Concurso
- TRE-MA
- Tipo
- Múltipla escolha
- Comentários
- Seja o primeiro a comentar
(1,0) 9 -
No POSTGRESQL, o índice do tipo B-tree é eficientemente usado quando uma consulta (query) utiliza operadores do tipo:
- a) = , < , <=, >, >=, BETWEEB, e IN
- b) #$
- c) * /
- d) ^^
- #119176
- Banca
- IESES
- Matéria
- Banco de Dados
- Concurso
- TRE-MA
- Tipo
- Múltipla escolha
- Comentários
- Seja o primeiro a comentar
(1,0) 10 -
Quando o POSTGRESQL executa uma consulta (query), faz-se necessária a escolha de uma estratégia para sua execução. Qual é o software do banco de dados encarregado de estabelecer a melhor estratégia para executar a consulta de forma eficiente?
- a) executer
- b) coacher
- c) dispatcher
- d) planner
- #119177
- Banca
- IESES
- Matéria
- Banco de Dados
- Concurso
- TRE-MA
- Tipo
- Múltipla escolha
- Comentários
- Seja o primeiro a comentar
(1,0) 11 -
Abaixo está representada a tabela Usuário;

Qual foi o comando executado?
- a) select nome, idade, count(id) from usuario where idPai = id
- b) select A.nome, A.idade, count(B.nome) as qtdFilhos from usuario A, usuario B where b.idPai = A.id group by A.nome
- c) select A.nome, A.idade, count(B.nome) as qtdFilhos from usuario A, usuario B where b.idPai = A.id
- d) select A.nome, A.idade, qtdFilhos from usuario A, usuario B where b.idPai = A.id
- #119178
- Banca
- IESES
- Matéria
- Banco de Dados
- Concurso
- TRE-MA
- Tipo
- Múltipla escolha
- Comentários
- Seja o primeiro a comentar
(1,0) 12 -
Observe a estrutura da tabela Veículo:
idVeiculo marca modelo potencia ano cor
1 Ferrari Enzo 660 2004 Vermelho
I. insert into veiculo (idVeiculo, marca, modelo, potencia, ano, cor) values (2, 'Ferrari', 'LaFerrari', 963, 2015, 'vermelho');
II. insert into veiculo values (2, 'Ferrari', 'LaFerrari', 963);
III. insert into veiculo values (2, 'Ferrari', 'LaFerrari', 963, 2015, 'vermelho');
IV. insert into veiculo (idVeiculo, marca, modelo, potencia, cor) values (2, 'Ferrari', 'LaFerrari', 963, 'vermelho');
Quantos comandos serão executados com sucesso?
- a) 1
- b) 2
- c) 4
- d) 3
- #119179
- Banca
- IESES
- Matéria
- Banco de Dados
- Concurso
- TRE-MA
- Tipo
- Múltipla escolha
- Comentários
- Seja o primeiro a comentar
(1,0) 13 -
No atual cenário econômico as empresas estão cortando todos os custos possíveis para evitar a demissão de funcionários.
Observe a estrutura da tabela Funcionário:
id nome TempoCasa
1 Rafael 11
2 Leandro 7
3 Fernanda 9
4 Bibiana 13
Observe a estrutura da tabela Dependente:
id nome idFuncionario
1 Cecília 1
2 Felipe 2
3 Odete 4
4 Edarci 3
Uma das formas encontradas pela empresa foi eliminar todos os dependentes dos funcionários com tempo de casa inferior a uma década. Qual o comando utilizado para realizar esta operação corretamente?
- a) delete from dependente tempoCasa < 10;
- b) delete from dependente where idFuncionario in (select id from funcionario where tempoCasa < 10);
- c) delete * from dependente D join funcionario F where idFuncionario = id and tempoCasa < 10;
- d) delete from dependente where idFuncionario not in (select id from funcionario where tempoCasa < 10);
- #119180
- Banca
- IESES
- Matéria
- Banco de Dados
- Concurso
- TRE-MA
- Tipo
- Múltipla escolha
- Comentários
- Seja o primeiro a comentar
(1,0) 14 -
Considere que na tabela Projeto tenham os seguintes dados:
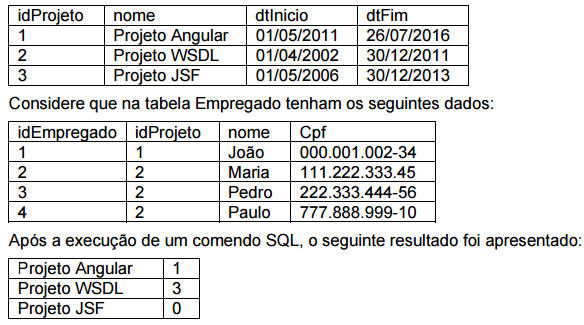
Qual a alternativa correta contém o comando executado para obter o resultado acima?
- a) select distinct P.nome, count(E.idProjeto) from projeto P right join empregado E on P.idProjeto = E.idProjeto group by E.idProjeto
- b) select P.nome, count(E.idProjeto) from projeto P left join empregado E on P.idProjeto = E.idProjeto group by E.idProjeto
- c) select distinct P.nome, count(E.idProjeto) from projeto P inner join empregado E on P.idProjeto = E.idProjeto group by E.idProjeto
- d) select P.nome, count(E.idProjeto) from projeto P, empregado E where P.idProjeto = E.idProjeto group by E.idProjeto
- #119181
- Banca
- IESES
- Matéria
- Banco de Dados
- Concurso
- TRE-MA
- Tipo
- Múltipla escolha
- Comentários
- Seja o primeiro a comentar
(1,0) 15 -
Observe a estrutura da tabela projeto:

Após a criação da tabela, constatou-se a necessidade de inclusão dos campos valor gasto e percentual de conclusão. Qual alternativa apresenta o comando correto?
- a) alter table projeto valorGasto double, percentConcluido double;
- b) alter table projeto add (valorGasto double, percentConcluido double);
- c) alter projeto add valorGasto double add percentConcluido double;
- d) alter table projeto add (valorGasto double, add percentConcluido double);